3.1 Executive Summary
The main business question we wished to explore with the NLP section relates to the different types of discussions that dominate the cryptocurrency subreddits - whether there is a difference between the enthusiasm/sentiment towards Dogecoin among them, the topics being discussed and how they react to major events, such as celebrity endorsements of these alternative currencies. A range of NLP techniques are used, ranging from regex-based word searches, topic modeling using LDA, TF-IDF, sentiment analysis and text embeddings.
General perception holds that r/CryptoCurrency is a subreddit with arguably higher quality information and more moderation, compared to r/dogecoin which has a lot of content related to ‘pumping’. The results do show that posts on r/CryptoCurrency have longer length, and contain more URLs compared to posts on r/dogecoin (which might indicate more citation
TF-IDF revealed that 'ceoofdogecoin' figures among the prominent terms indicating this relation as Musk is often referenced as the CEO of Dogecoin. Among the topics that surfaced through topic modeling, there again were references to Musk. As the most well know meme coin, the discussion of other meme coin take a large proportion of the discussion in Dogecoin community, it is usually linked with strong buy signal. We further evaluated this relationship by trying to understand the variation in sentiment that was brought about by a particular tweet of Musk. The analysis is contained in these next pages, each focusing on a distinct question that we explore in the data.
3.2 Basic NLP and Text Checks
Prior to diving into our natural language processing analysis, we performed a series of fundamental text examinations and analyses on the dataset.
3.2.1 Distribution of Text Length
Using a user-defined function to determine the length of each document, we analyze the distribution of text length across submissions and comments. On average, posts related to dogecoin have approximately 110 words, the average comment length is 11.9 words, and the title length is an average of 9.3 words.
Table 1. Summary statistics of post/comment lengths
| Text | Average | Maximum | Minimum |
| Posts | 109.98 | 5532 | 1 |
| Comment | 11.9 | 1404 | 1 |
| Title | 9.3 | 80 | 1 |
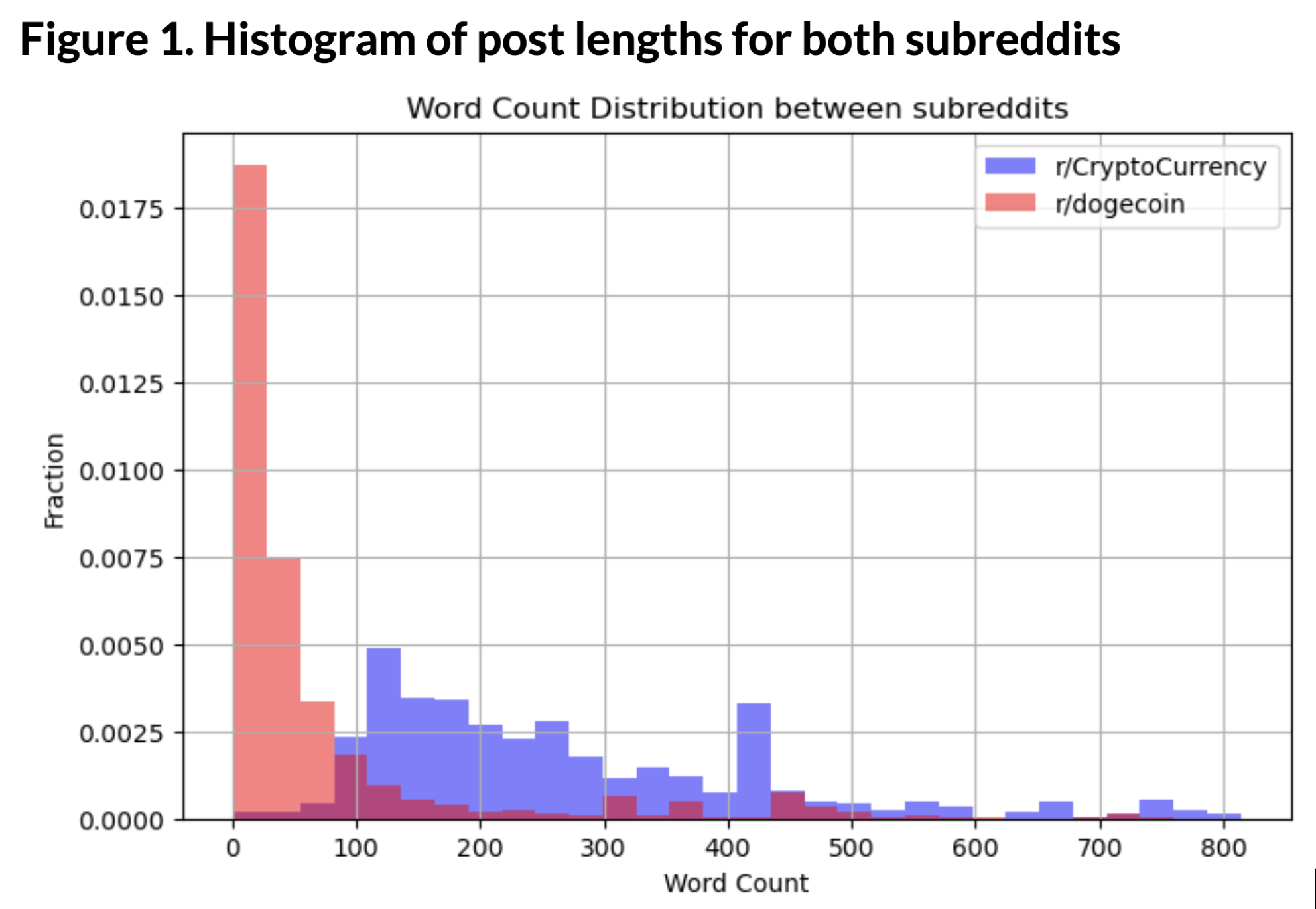
The following histogram plots the distribution of text lengths in posts and comments, colored according to the subreddit where it is posted. As the following diagram shows a striking contrast - the majority of very short length posts are more prevalent in r/dogecoin, while r/CryptoCurrency posts are on the longer end of the distribution. This might indicate that r/CryptoCurrency has higher-quality or higher-information posts than r/dogecoin.
Figure 1. Histogram of post lengths for both subreddits
3.2.2 Frequent Words
By breaking down and spreading out the words from the clean output of our pipeline, we counted the most commonly occurring words for both submissions and comments.
Figure 2: Top 10 most frequently used words
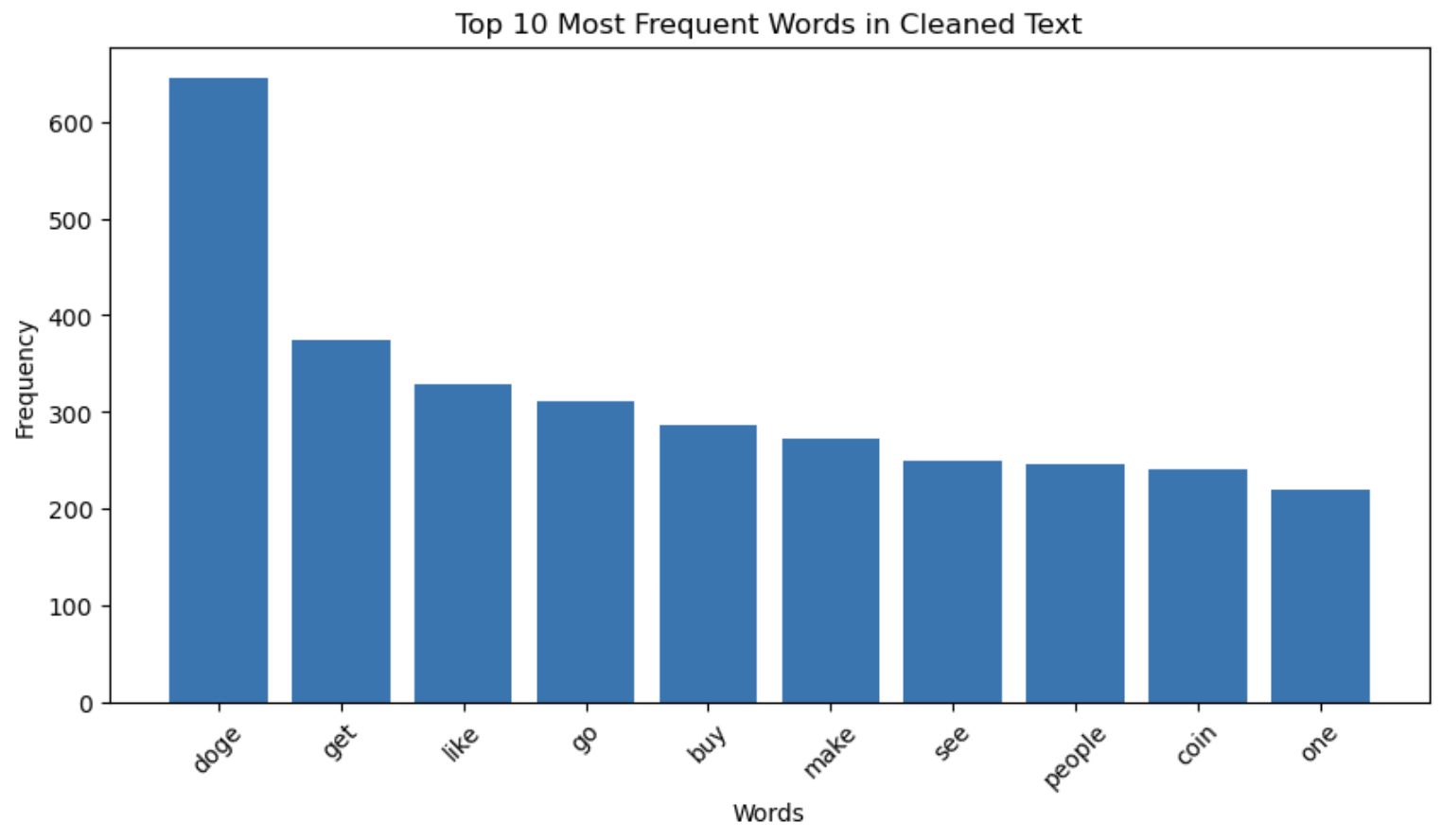
Note: (based on a sample)
3.2.3 URLs
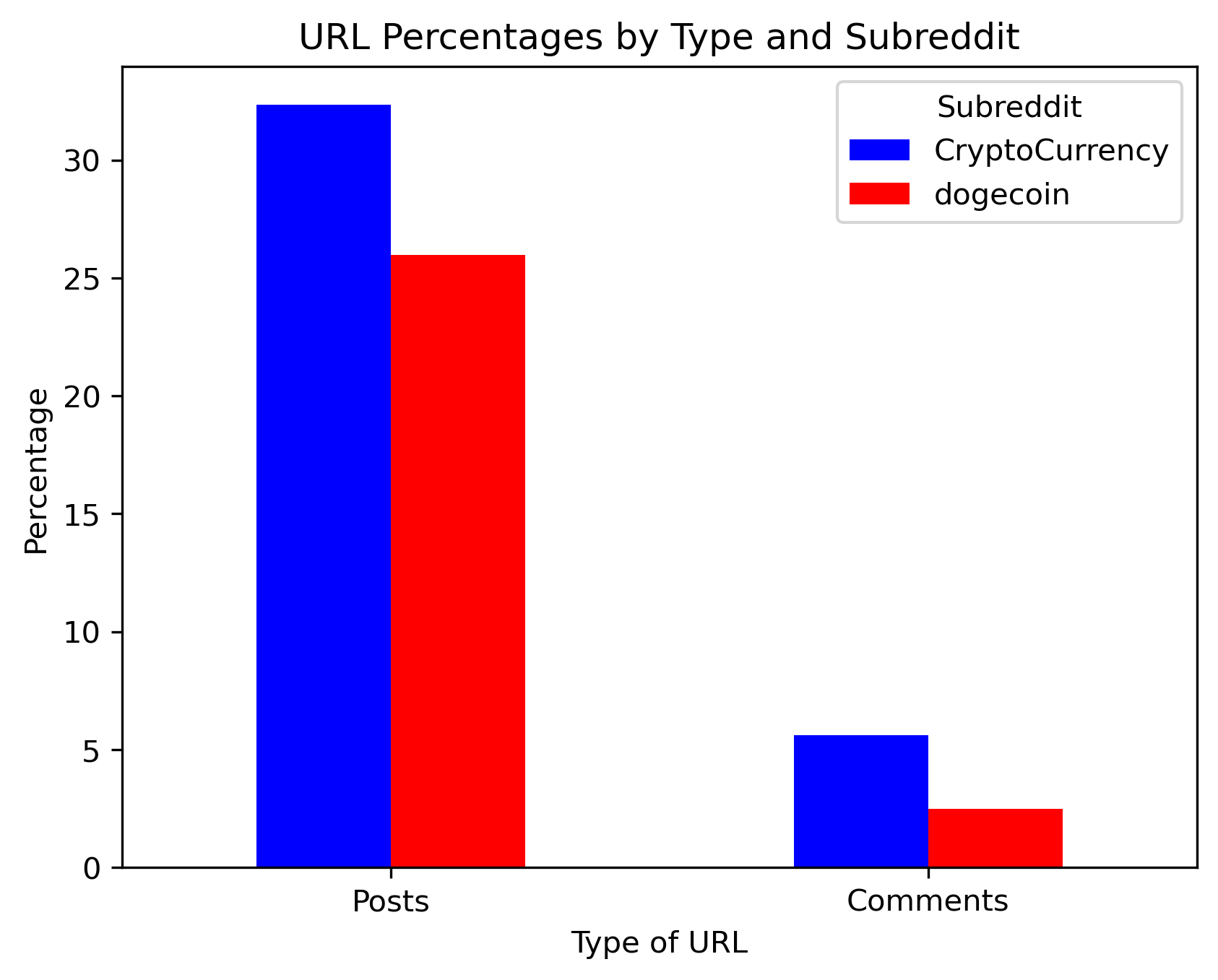
Based on regex-based search of URLs, we find that a higher percentage of posts and comments in r/CryptoCurrency contain URLs than those in r/dogecoin. This hints - but does not confirm - our hypothesis that posts in r/dogecoin may have lesser quality information, or lesser citations and external links to support their information.
Figure 3: Bar graph of share of posts containing URLs
3.3 Q4 Term Frequency-Inverse Document Frequency (TF-IDF)
To run a TF-IDF, we used Spark-NLP Processing Job because of the huge dataset size with the HashingTF feature transformer. When using Spark’s HashingTF feature transformer, the challenge is that it hashes words into a fixed-size feature vector. This hashing process makes it efficient but also means you lose the direct mapping between words and their indices in the feature vector, which can make it difficult to retrieve the original words from the indices.
Table 2: Top 10 Words by TF-IDF Scoring: Highlighting Unique Vocabulary
| Term | Frequency | |
| 0 | blockchain | 2159.020063 |
| 1 | burning | 1217.472828 |
| 2 | adventures | 988.120861 |
| 3 | above | 969.387716 |
| 4 | buffet | 968.732854 |
| 5 | are | 927.111189 |
| 6 | ceoofdogecoin | 870.622154 |
| 7 | 240k | 827.099049 |
| 8 | announces | 817.186108 |
| 9 | career | 780.541266 |
(Term frequency from sample dataset)
3.4 Q5. Exploring the primary topics
NLP pipeline
In our text data processing workflow, we leveraged the Spark NLP library from John Snow Labs to construct a comprehensive pipeline for cleansing and standardizing our text data. The steps included in this pipeline are as follows:
1. DocumentAssembler(): This is the initial stage that transforms raw input text into a format that Spark NLP can utilize, effectively converting it into annotated documents.
2. Tokenizer(): This stage segments the text into individual elements or tokens, usually words, which are the basic units for NLP tasks.
3. Normalizer(): Here, various normalization techniques are employed to standardize the text. This includes converting all characters to lowercase, eliminating punctuation or special characters, and other cleaning procedures.
4. StopWordsCleaner(): This component is crucial for removing stopwords—commonly occurring words in a language that offer little value for many analytical purposes, such as “is,” “and,” or “the.”
5. Stemmer(): By including a stemmer, the pipeline reduces words to their base or root form, which can often aid in consolidating variations of a word to a single representative form.
6. Finisher(): Acting as a crucial terminal component, the Finisher extracts the processed data from the Spark NLP’s structured format and converts it back into a more familiar array of tokens, suitable for further analytical operations or machine learning tasks.
As we construct our machine learning pipeline, these stages are executed in sequence, ensuring a smooth flow from raw text to a cleansed and standardized token array.
Topic Modeling
Topic modeling on Dogecoin-related discussions uncovers several primary topics, including market predictions, community projects, and technological developments. These insights highlight the multifaceted nature of the discourse, extending beyond mere investment discussion.
To address this query, we implemented a Latent Dirichlet Allocation (LDA) Model, a probabilistic approach for topic modeling that uncovers latent topics within a corpus of documents.
LDA posits that each document is composed of a limited number of topics, with each topic being a probability distribution over words. This model represents each document through its topic distribution and each topic through its word distribution. By evaluating these distributions, LDA is able to pinpoint the predominant topics across the documents, even when these topics aren’t explicitly stated in the text. (need to be revised - add pros /cons)
We utilized the LDA function from pyspark.ml.clustering to build our model, applying it to the cleaned dataset from our NLP pipeline. Our model was configured to identify 4 distinct topics.
Table 3: Topic modeling results for posts
| Topic | Topic Words | Summary |
| 0 |
|
Believe in doge would keep rising and advocate users to hold |
| 1 |
|
Discussion about other meme coins |
| 2 | doge, crypto, gui, wallet, robinhood, happe, dont, tip, think |
Usage of cold wallet and brokers like robinhood |
| 3 |
|
Elon Musk’s twitter content |
| 4 |
|
New published cryptos |
Interpreting the results of topic modeling exercises is not straightforward, as we basically get a bag of words without any specific meaning. However, it is possible to make an informed guess about what ‘topics’ these might refer to, as outlines below.
Topic 1: Dogecoin Enthusiasm and Investment Strategies
As the popularity of Dogecoin continues to rise, many supporters believe in its long-term growth and encourage holding the cryptocurrency as an investment. This topic could likely cover the sentiments and strategies of crypto investors who are optimistic about Dogecoin’s potential to reach new heights, commonly referred to as going “to the moon.”
Topic 2: Exploring the World of Meme Coins Beyond Dogecoin
This topic could possibly be delving into various other meme coins like Banano, discussing their potential and place in the crypto market. These lesser-known coins often foster unique communities.
Topic 3: Practical Tips on Using Cryptocurrency Wallets and Brokers
Focusing on the practical aspects of managing cryptocurrencies, this topic seems like it addresses the use of cold wallets for security and brokers like Robinhood for transactions.
Topic 4: Influence of Elon Musk on Dogecoin
Elon Musk’s engagement with Dogecoin through Twitter has significantly influenced its market movements. This topic shows distinctly that Elon Musk - likely through tweets and public endorsements - is a key figure in Dogecoin’s discourse. Discussions often speculate on his future involvement and its potential impacts on the cryptocurrency, highlighting the interplay between celebrity influence and crypto market dynamics.
Topic 5: Updates and Discussions on New Cryptocurrencies
This topic is a platform for daily updates and discussions on new and emerging cryptocurrencies. It captures the excitement and speculation surrounding new entries into the market, with a particular focus on how they compare or contrast with established players like Dogecoin.
Table 4: Topic modeling results for comments
| Topic | Topic Words | Summary |
| 0 | remov, doge, verifi, +usodogetip, ampxb, yes, let, on, yeah, dogecoin |
Other meme token |
| 1 |
|
Banano token, belief in dogecoin price |
| 2 | doge, crypto, dont, people, year, get, buidl, go, monei, coin |
Advocate users to hold crypto and don’t sell |
The comment is different from the post, which only contains three main topics, which is understandable since comment usually only represent attitude to post content. Generally, it only includes the bullish emotion of the crypto market and talking about other meme coin. Some strong meme coin may be mentioned too much time that they can be considered as a individual topic.
3.5 Q6: Exploring the sentiments and event study
3.5.1. What sentiments are prevalent in posts about Dogecoin, and did they change in response to major events?
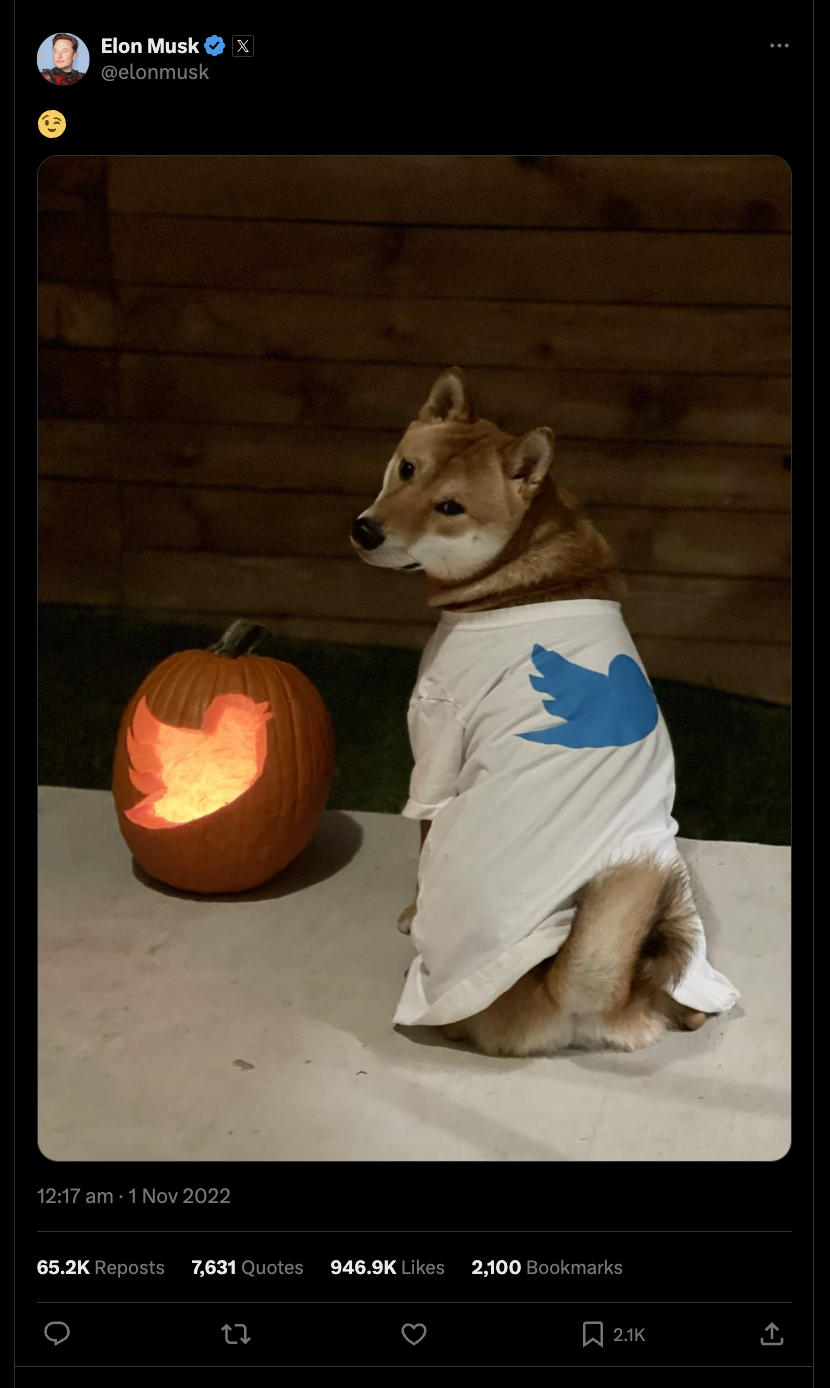
Elon Musk has been a vocal proponent of Dogecoin, frequently discussing and promoting the cryptocurrency on social media, which often influences its market value. His tweets and comments can cause significant fluctuations in the price of Dogecoin, demonstrating his substantial impact on the crypto market. Musk’s endorsement has helped to elevate Dogecoin from a lesser-known digital currency to a prominent player in the cryptocurrency space. In the early hours of November 1, 2022 (just after 12 AM), Musk tweeted a picture of Shiba wearing a Twitter T-shirt which likely led to an uptick in dogecoin’s price. We look at the nature of posts before and after this event. Using sentiment analysis, we calculate a compound average score - where higher value indicates more positive sentiment.
Figure 4: Lineplot of change in average sentiment score
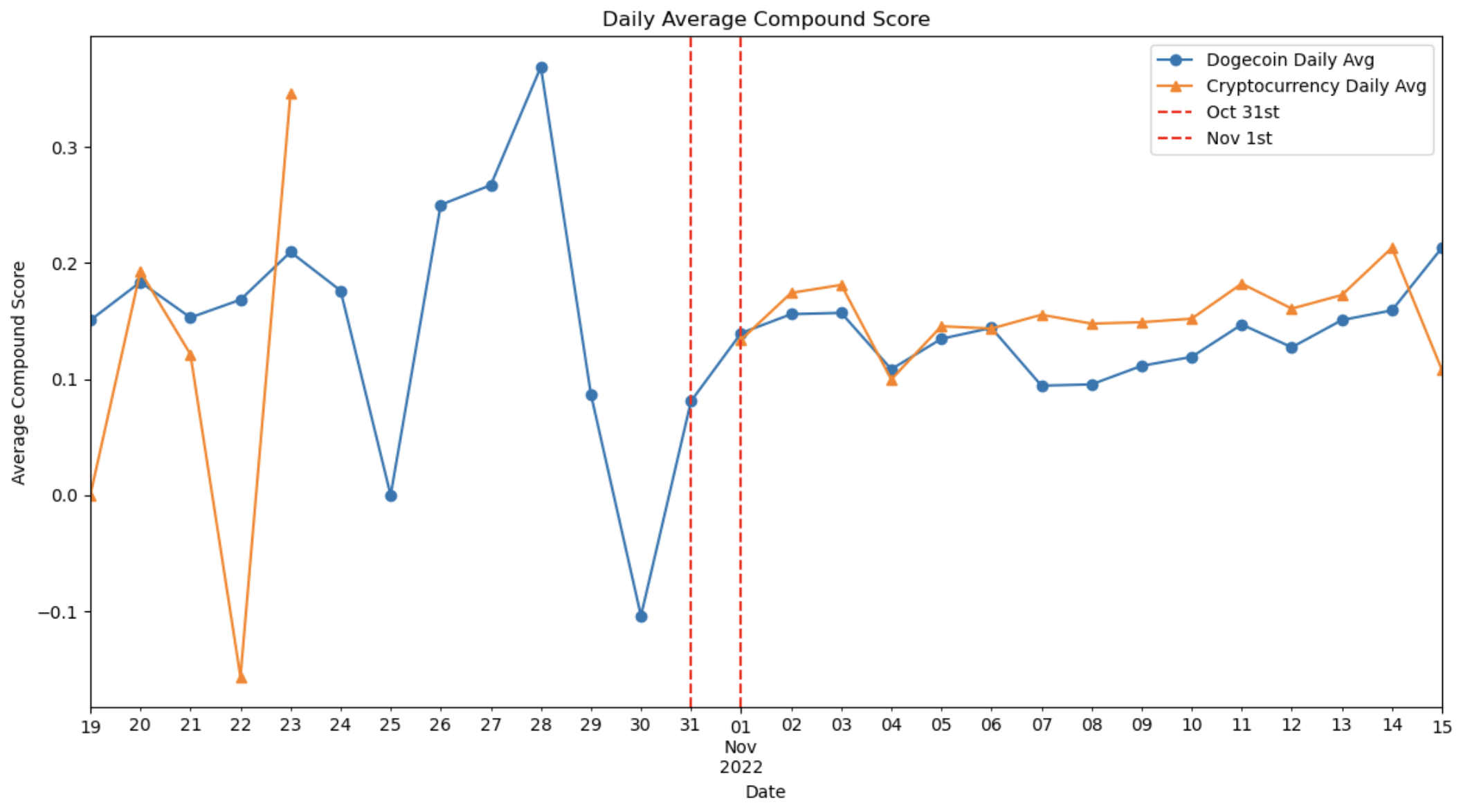
We are able to make a few observations, by isolating our view to a window of 14 days before and after November 1, 2022, when the tweet was made. Activity on r/CryptoCurrency with respect to posts containing the word doge had seen a revival after the tweet. It was seen that for several days before the tweet, doge activity on that subreddit had virtually hit a snooze. We see a revival in activity for both subreddits aligning with when the tweet was made alongwith a sustained average sentiment score being maintained.
3.5.2. Do highly active users in both subreddits post distinct content?
In the realm of natural language processing, embeddings are high-dimensional vectors used to capture the semantic properties of text. These vectors transform textual data into a format that machines can ‘understand’. From the results of the Spark Processing Job earlier, we generate embeddings of the post titles using BERT Sentence Embeddings trained on Wikipedia and BooksCorpus and fine-tuned on SST-2.
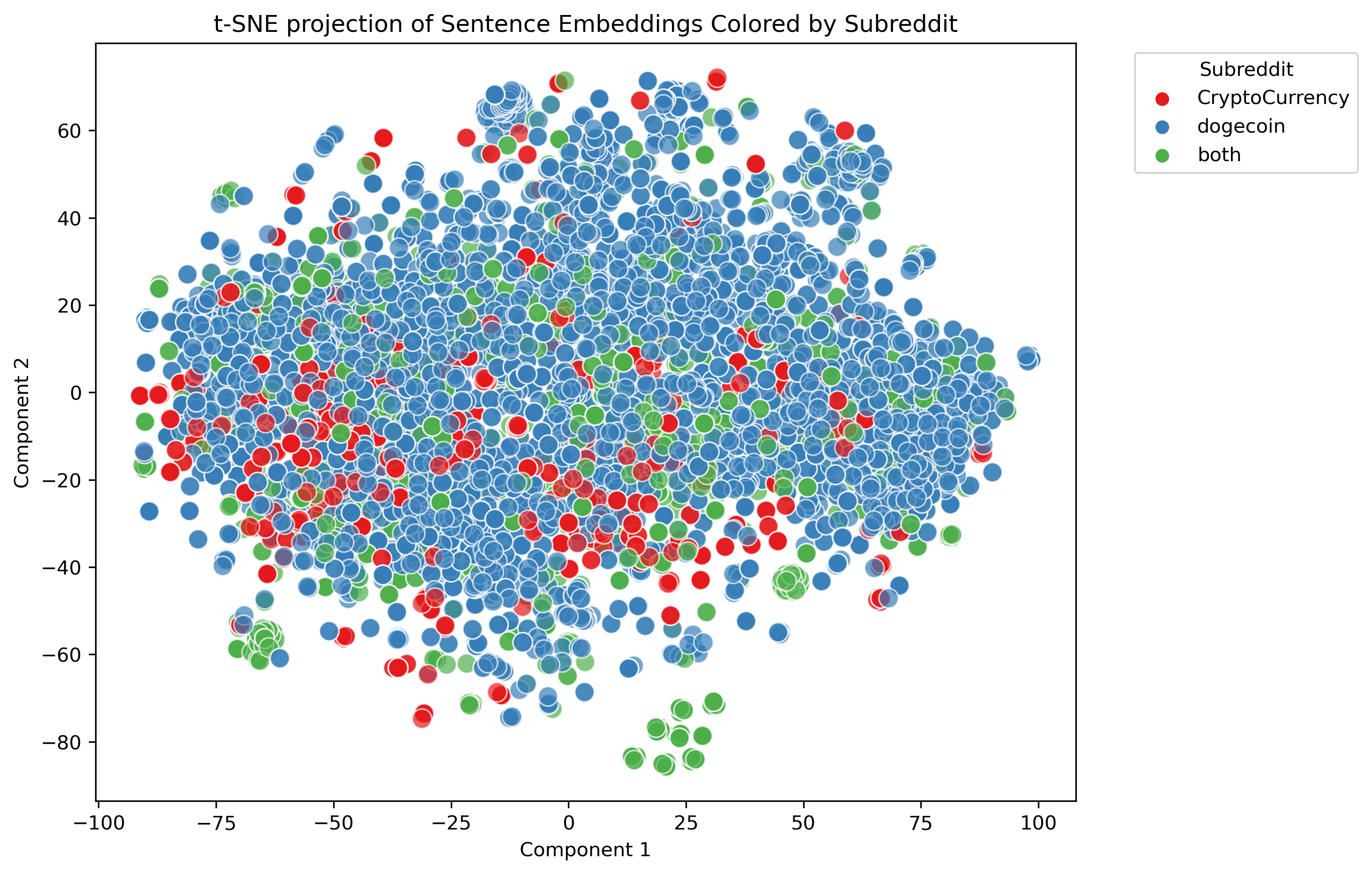
To aid in visual interpretation of these embeddings, the dimensionality reduction technique known as t-SNE (t-distributed Stochastic Neighbor Embedding) is employed. This method reduces the complex, high-dimensional data into a 2-dimensional space, enabling easier visualization and analysis of the relationships and clusters within the data, such as differentiating textual content across various subreddits.
This generates a column containing 768-dimensional vector which represents the text. To easily visualize it, we use t-SNE to reduce the embeddings to 2 dimensions and plot them. The color represents membership of different subreddits. We have three groups of users: those who are only part of r/CryptoCurrency (red), those only part of r/dogecoin (blue) and the highly active users who are part of both subreddits (green). However, as the plot shows, the posts of highly active users are not distinctly different in content/meaning compared to users who are only active in one subreddit.
Figure 5. Scatter plot of t-SNE embeddings of post titles
Elon Musk has been a vocal proponent of Dogecoin, frequently discussing and promoting the cryptocurrency on social media, which often influences its market value. His tweets and comments can cause significant fluctuations in the price of Dogecoin, demonstrating his substantial impact on the crypto market. Musk’s endorsement has helped to elevate Dogecoin from a lesser-known digital currency to a prominent player in the cryptocurrency space. In the early hours of November 1, 2022 (just after 12 AM), Musk tweeted a picture of Shiba wearing a Twitter T-shirt which likely led to an uptick in dogecoin’s price. We look at the nature of posts before and after this event. Using sentiment analysis, we calculate a compound average score - where higher value indicates more positive sentiment.